In this tutorial, we’ll build a multi-pipeline DAG to train a regression model on housing market data to predict the value of homes in Boston. This tutorial builds on the skills learned from the previous tutorials, (Standard ML Pipeline and AutoML Pipeline.
Before You Start #
- You must have Pachyderm installed and running on your cluster
- You should have already completed the Standard ML Pipeline tutorial
- You must be familiar with jsonnet
- This tutorial assumes your active context is
localhost:80
Tutorial #
Our Docker image’s user code for this tutorial is built on top of the civisanalytics/datascience-python base image, which includes the necessary dependencies. It uses pandas to import the structured dataset and the scikit-learn library to train the model.
Each pipeline in this tutorial executes a Python script, versions the artifacts (datasets, models, etc.), and gives you a full lineage of the model. Once it is set up, you can change, add, or remove data and Pachyderm will automatically keep everything up to date, creating data splits, computing data analysis metrics, and training the model.
1. Create an Input Repo #
2. Create the Pipelines #
We’ll deploy each stage in our ML process as a Pachyderm pipeline. Organizing our work into pipelines allows us to keep track of artifacts created in our ML development process. We can extend or add pipelines at any point to add new functionality or features, while keeping track of code and data changes simultaneously.
1. Data Analysis Pipeline #
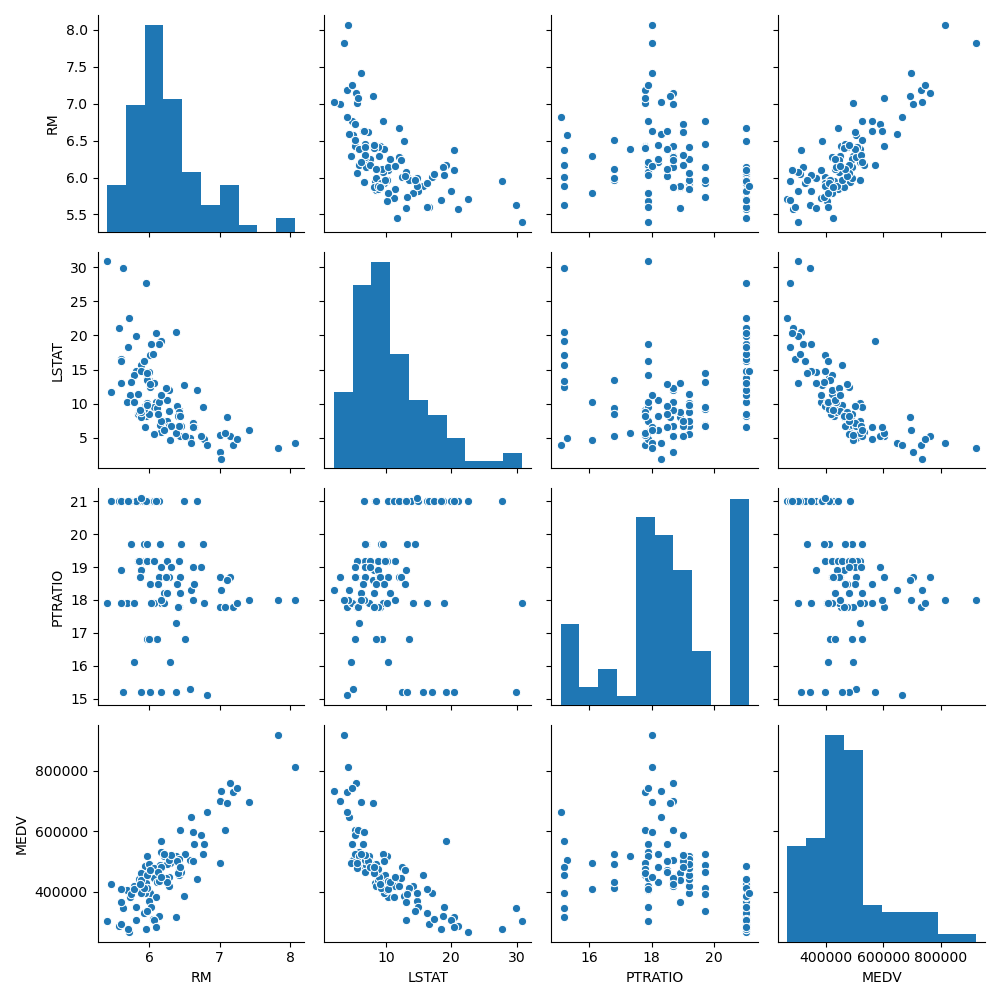
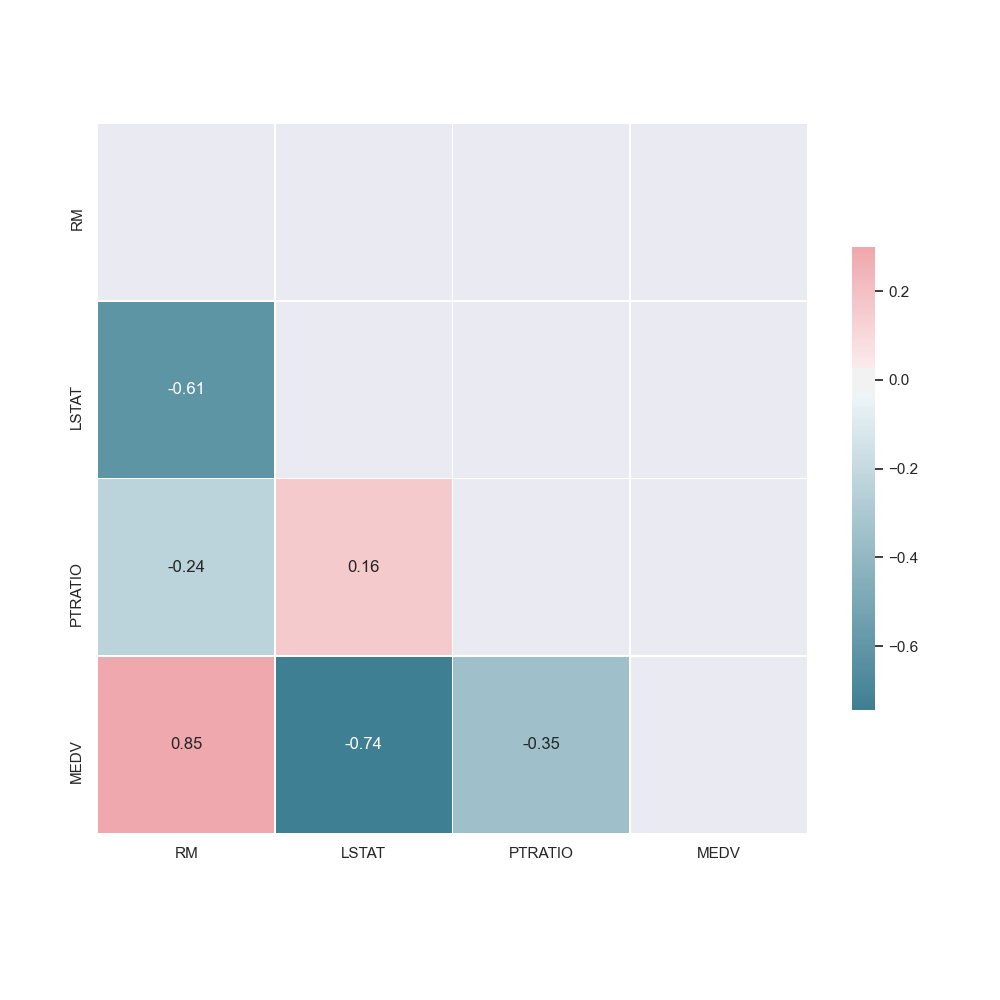
The data analysis pipeline creates a pair plot and a correlation matrix showing the relationship between features. By seeing what features are positively or negatively correlated to the target value (or each other), it can helps us understand what features may be valuable to the model.
2. Split Pipeline #
Split the input csv files into train and test sets. As we new data is added, we will always have access to previous versions of the splits to reproduce experiments and test results.
Both the split pipeline and the data_analysis pipeline take the csv_data as input but have no dependencies on each other. Pachyderm is able to recognize this. It can run each pipeline simultaneously, scaling each horizontally.
3. Regression Pipeline #
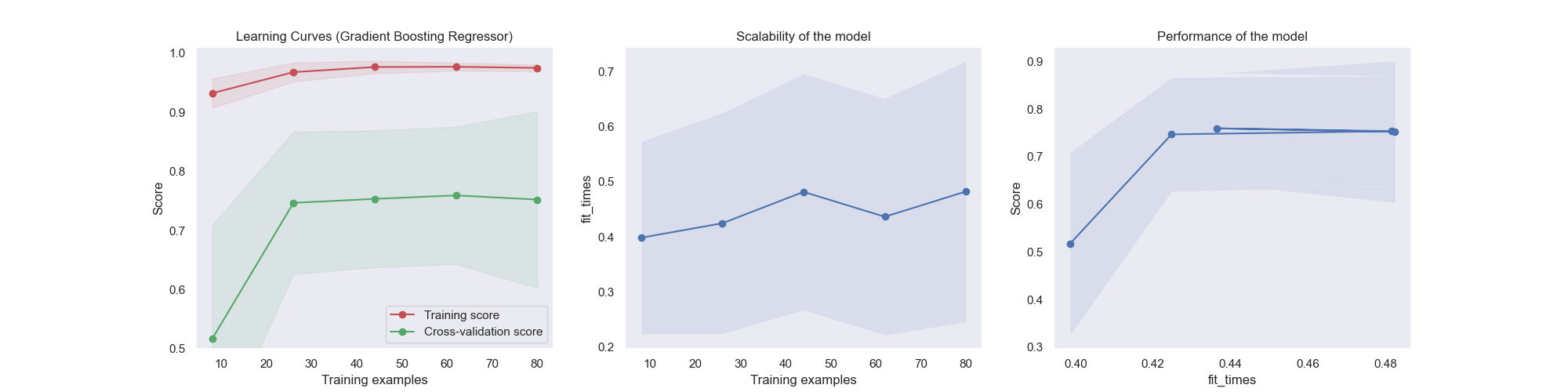
To train the regression model using scikit-learn. In our case, we will train a Random Forest Regressor ensemble. After splitting the data into features and targets (X and y), we can fit the model to our parameters. Once the model is trained, we will compute our score (r^2) on the test set.
After the model is trained we output some visualizations to evaluate its effectiveness of it using the learning curve and other statistics.
3. Upload the Dataset #
4. Download the Results #
Once the pipeline has finished, download the results.
5. Update the Dataset #
6. Inspect the Data #
We can use the diff command and ancestry syntax to see what has changed between the two versions of the dataset.
pachctl diff file csv_data@master csv_data@master^Bonus Step: Rolling Back #
If you need to roll back to a previous dataset commit, you can do so with the create branch command and ancestry syntax.
pachctl create branch csv_data@master --head csv_data@master^User Code Assets #
The Docker image used in this tutorial was built with the following assets: