About #
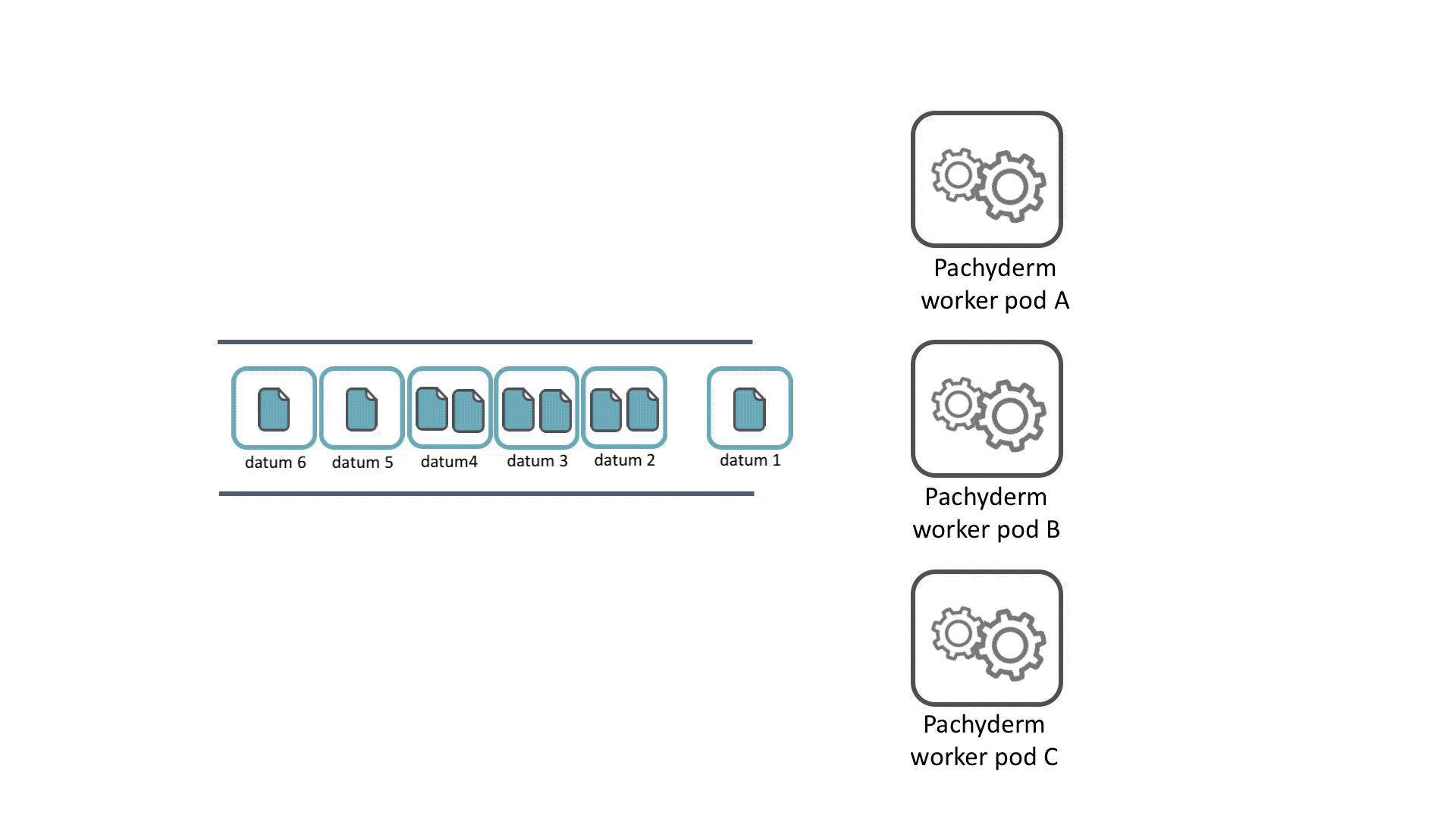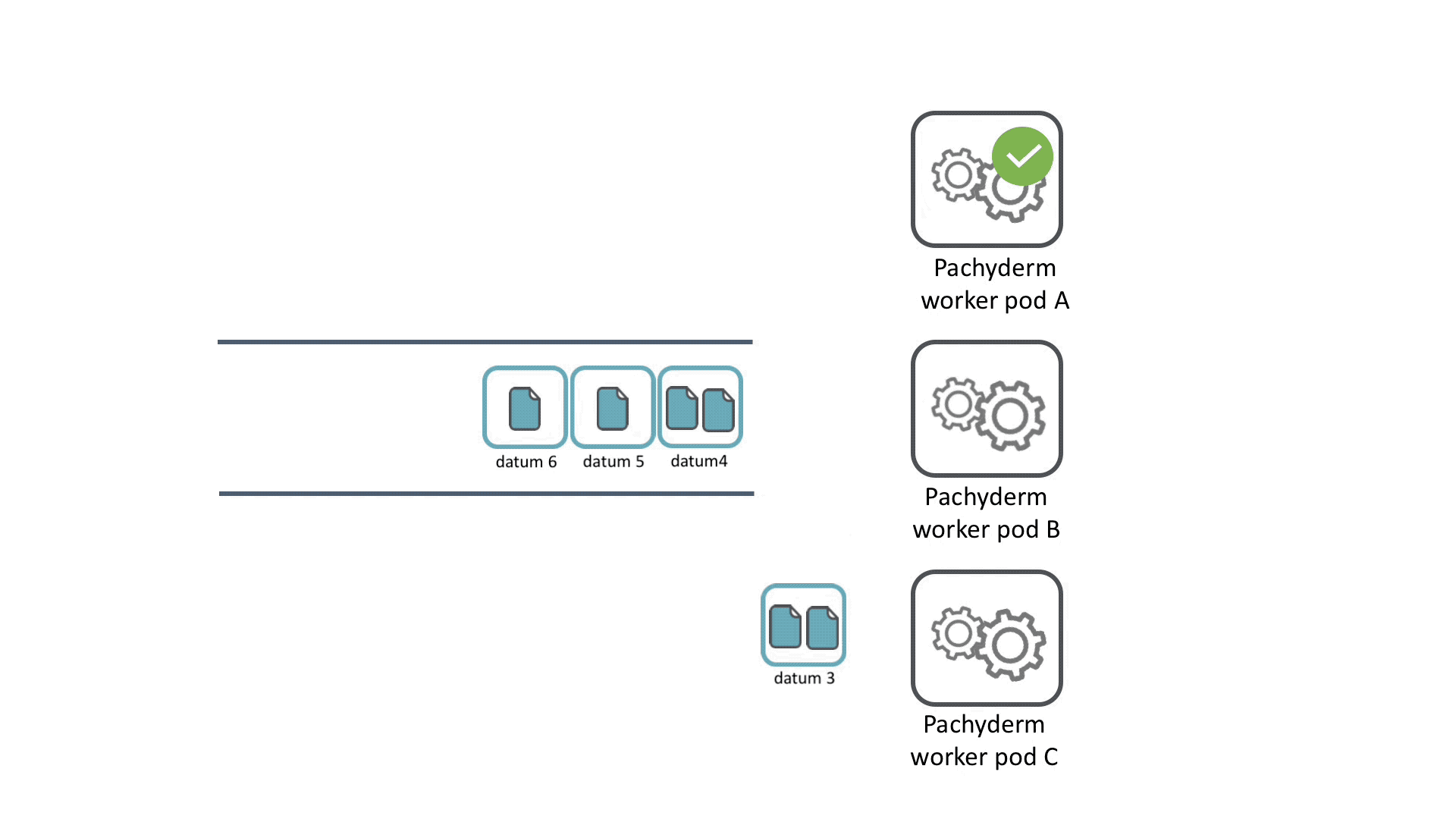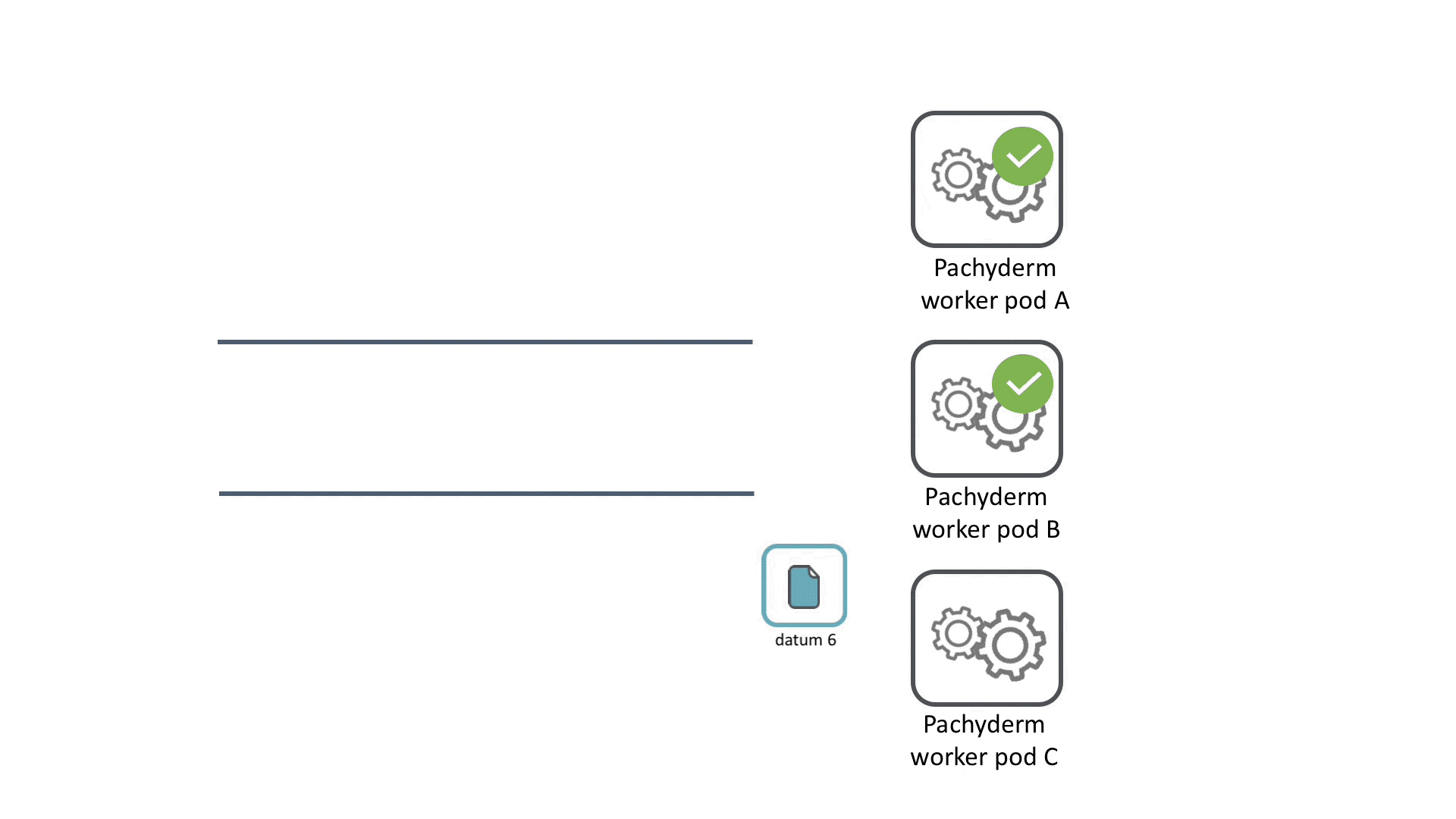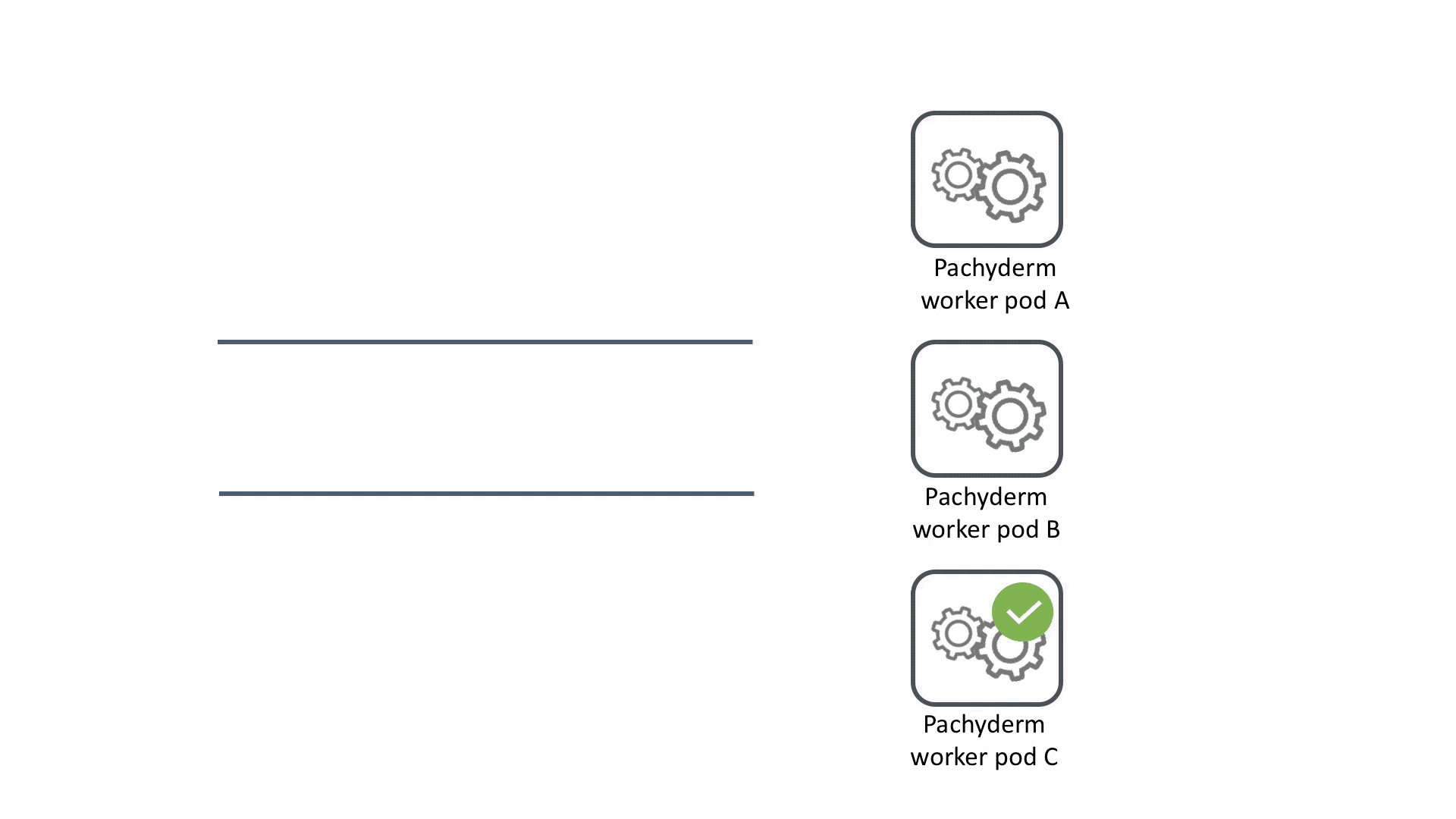
Distributed computing is a technique that allows you to split your jobs across multiple Pachyderm workers via the Parallelism PPS attribute. Leveraging distributed computing enables you to build production-scale pipelines with adjustable resources to optimize throughput.
For each job, all the datums are queued up and then distributed across the available workers. When a worker finishes processing its datum, it grabs a new datum from the queue until all the datums complete processing. If a worker pod crashes, its datums are redistributed to other workers for maximum fault tolerance.