
It is important to note that this use case is limited to simple cases where the “bad” changes were made relatively recently, as any pipeline update since then will make it impossible.
In rare cases, you might need to delete a particular file from a given commit and further choose to delete its complete history. In such a case, you will need to:
Create a new commit in which you surgically remove the problematic file.
Start a new commit:
pachctl start commit <repo>@<branch>
Delete all corrupted files from the newly opened commit:
pachctl delete file <repo>@<branch or commitID>:/path/to/filesFinish the commit:
pachctl finish commit <repo>@<branch>
Optionally, wipe this file from your history by squashing the initial bad commit and all its children up to the newly finished commit.
Unless the subsequent commits overwrote or deleted the bad data, the data might still be present in the children commits. Squashing those commits cleans up your commit history and ensures that the errant data is not available when non-HEAD versions of the data are read.
Example #
In the simple example below, we want to delete file C in commit 2. How would we do that?
For now, pachctl list file repo@master returns the files A’, B, C’, E, F.
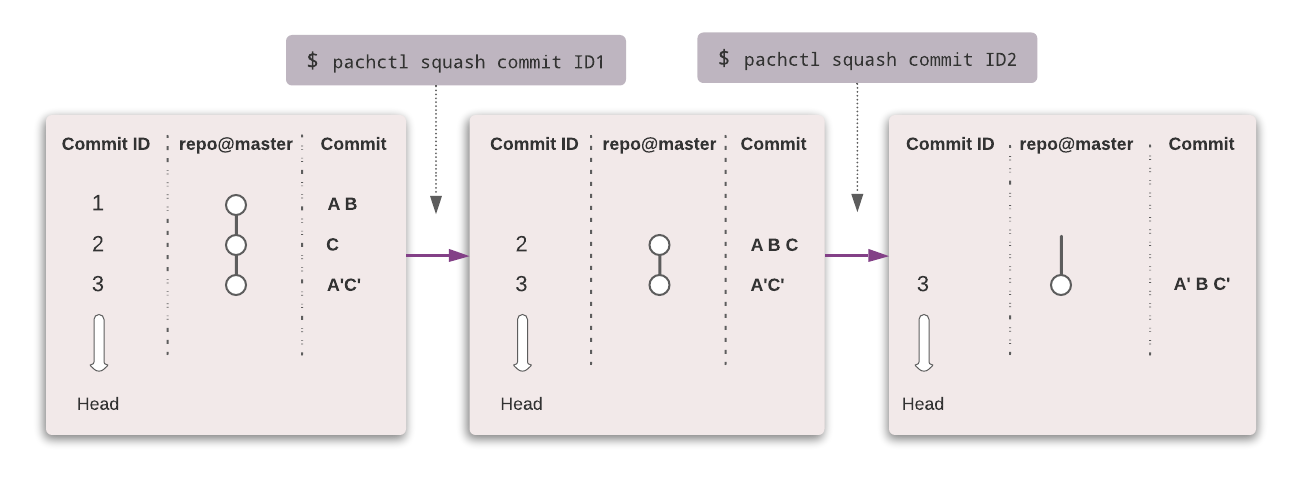
- A’ and C’ are altered versions of files A and C.
We create a new commit in which we surgically remove file C:
pachctl start commit repo@master pachctl delete file repo@master:path/to/C pachctl finish commit repo@masterAt this point,
pachctl list file repo@masterreturns the files A’, B, E, F. We removed file C. However, it still exists in the commit history.To remove C from the commit history, we squash the commits in which C appears, all the way down to the last commit.
pachctl squash commitID2 pachctl squash commitID3It is as if C never existed.